Yoshua Bengio and Yann LeCun were giving this tutorial as a tandem talk.
The tutorial started off by looking at what we need in Machine Learning and AI in general. Two key points were identified:
- Distributed representation
- Compositional models
The inspiration for Deep Learning was that concepts are represented by patterns of activation. Hidden units in a neural networks discover semantically meaningful concepts.
Question: Why this is the case. Is this a side-effect/incidence and an empirical observation or is there some sort of mathematical proof behind this statement?
The tutorial continued by highlighting that nonparametric methods are completely intractable: For 

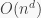
Question: What happens if we are interested in generalization?
Depth gives you an advantage because some functions can be represented quite efficiently using deep architectures.
Some assumptions about the data-generating distribution need to be made, but there were no details about this.
Training of DNNs is done by backpropagation
- SGD: small batch of samples at a time, gradient for this sample, update parameters
- The chain-rule is all over the place
Some tricks to make backpropagation work (better):
- Cross-entropy loss for classification
- Shuffle samples to make SGD work
- Normalize the data
Unfortunately, no further insights were given why these methods work.
An important feature of the success of DNNs is the availability of software (Torch, TensorFlow, Theano, …), which typically comes with an automatic differentiation tool
Convolutional Neural Networks
The motivation for using hierarchies is that natural signals are compositional. Therefore “convnets are naturally hierarchical…”.
A convolutional neural network is a stack of modules:
Normalization 
The pooling module computes some statistic of a small neighborhood of the feature in the previous layer (e.g., max, average, …). This will cause the spatial resolution to go down, and the number of features goes up; this leads to some shift-invariance. Convolutions can be applied to 1D-3D arrays, which appear in various data streams (music, speech, images, videos).
Recurrent Nets
The assumption behind recurrent nets is to think about time-invariant dynamical systems

where 
An RNN can also be considered a fully connected directed graphical model, and 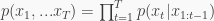
Long-term dependencies appear due to the application of the chain-rule, but there are some problems: If the singular values of Jacobians 
They went into various tricks that can be used to address this issue. Here are some:
- Make the networks much bigger and regularize them like crazy works.
- Batch normalization
- Random search for hyper-parameters. Could work better than Bayesian optimization.
- Distributed training: Large minibatches + 2nd-order natural gradients; asynchronous SGD (data parallelism vs model parallelism)
Yoshua then showed lots of computer vision applications. It was quite interesting to hear that until 3 years ago, nearly nobody used convnets for computer vision, nowadays it is everybody because they simply work. As an example, he mentioned that the Tesla autopilot also uses convnets. At Facebook every picture goes through two convnets (object recognition, face recognition).
There is a version of a convnet, the multi-scale convnets, which use the same image at various resolutions, simultaneously processed.
Deep Convolutional Networks
In face recognition not all categories are known at training time. One way of addressing this is metric learning. For this, two different images of the same person are used, and the network is trained to minimize the distance between them. Then, two images of different people are used, and the network is being told tat they are different.
When looking at the Euclidean vector space of NN features, there are some interesting observations by looking at directed segments/geometric vectors in feature space:
King – Queen = Man – Woman
Rome – Italy = Paris – France
If we look only at the Euclidean distances in feature space, we can see some commonalities.
Question:
- Why is the feature space a Euclidean vector space in the first place?
- Why do Euclidean distances (with the standard scalar product) in a nonlinear feature space produce anything meaningful?
- Are these similarities just some positive examples or is there perhaps an underpinning theory supporting this statement?
Toward the end of the tutorial, a few recent developments were discussed:
- Memory networks for reasoning, where the REINFORCE algorithm is used (Yoshua gave also a talk at the Deep RL workshop where he discussed this in more detail).
- Transfer Learning is phrased as an unsupervised deep learning problem, so all the tools can be used.
- Multi-task learning. Here lower layers of the neural net are shared. By using the underlying features at the top level at the shared part, we can combine multiple sources of evidence with shared representations, and learn mappings between representations. For instance, different modalities (sound, text) . This allows for 0-shot generalization to new categories
- Unsupervised Representation Learning. There is lots of unlabeled data. Automatic discovery of the underlying structure can be done by using causality: If
is a cause of
, you can use the unlabeled examples of to learn a classifier for
Summary
The reason why I went to the tutorial was that I wanted to learn a bit more about the intricate details that make deep nets work. The tutorial was giving not so many insights but more a list of tricks, lots of which seemed to me good heuristics. The tutorial covered a lot of material and showed lots of applications of DNNs, but I personally would have preferred a more detailed tutorial that motivates some of the choices to a research research talk.
