Manuel Watter, Jost Tobias Springenberg, Joschka Boedecker, Martin Riedmiller:
Embed to Control: A Locally Linear Latent Dynamics Model for Control from Raw Images
arXiv, 2015
This paper deals with the problem of model-based reinforcement learning (RL) from images. The idea behind model-based RL is to learn a model of the transition dynamics of the system/robot and use this model as a surrogate simulator. This is helpful if we want to minimize experiments with a (physical/mechanical) system. The added difficulty addressed in this paper is that this predictive transition model should be learned from raw images where only pixel information is available.
Central idea
The approach taken in this paper follows the idea of Deep Dynamical Models (DDM) [1,2]: Instead of learning predictive models for images directly, a detour via a low-dimensional feature space is taken: Images are embedded into a lower-dimensional feature space via a deep auto-encoder. A transition model 


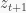

Latent feature representation
Given the results from stochastic optimal control theory, it remains to find a suitable low-dimensional representation of the image. This latent representation 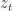

- It must be sufficiently rich to be able to reconstruct
- It must allow for accurate predictions of the next feature
- The prediction of the next latent state must be locally linearizable for all valid magnitudes of the control signal
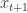

The authors consider distributions 
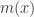
A challenge identified in the paper is that it is quite complicated to address points 2. and 3. from above by learning features and subsequently good nonlinear transformations that satisfy these points. Therefore, the authors propose to directly impose the desired properties on the feature representation
For sampling latent states from the posterior 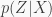

$latex
\mu_t = W_\mu h(x_t) + b_\mu\\
\log\sigma_t = W_\sigma h(x_t) + b_\sigma,$
where 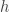
Predictions in latent space
Given the Gaussian representation of the latent state
Hypothesizing and reconstructing images
Given the predictive feature distribution 
Transition model
Watter et al. choose a neural network for a transformation mapping that predicts the local linearization matrices. The full information flow of the model is given in the figure below (taken from the paper).

Training
For training the model the following loss function is minimized:

where 
Comments
The approach presented here is neat: Learning a compact feature representation and transition models for model-based RL is similar to [2], but this paper goes further by implementing an approximate (variational) inference scheme to deal with noise and potential model errors (e.g., overfitting). Once a model is learned, optimal control strategies (e.g., iLQG, (N)MPC, DDP) can be applied, and simplify the (model-free) RL problem of finding optimal controllers. Note that in model-based methods we do not necessarily need explicit value function representations, which makes life a bit easier. A somewhat surprising point is that the authors concatenate images 
The results in the paper are very promising. The findings of this paper that we need to jointly train the encoder/decoder model and the transition model agree with [1].
What remains unclear at the moment:
- Transition model: Why do we need to predict the linearization matrices using another neural network? Why not directly linearizing the transition mapping at
?
References
[1] N. Wahlström, T. B. Schön, M. P. Deisenroth:
Learning Deep Dynamical Models From Image Pixels
IFAC Symposium on System Identification, 2015
[2] N. Wahlström, T. B. Schön, M. P. Deisenroth:
From Pixels to Torques: Policy Learning using Deep Dynamical Models
arXiv, 2015
[3] D. P. Kingma, M. Welling:
Auto-Encoding Variational Bayes
ICLR, 2014
[4] D. Jiminez-Rezende, S. Mohamed, D. Wierstra:
Stochastic Backpropagation and Approximate Inference in Deep Generative Models
ICML, 2014
[5] E. Todorov, W. Li:
A Generalized Iterative LQG Method for Locally-Optimal Feedback Control of Constrained Nonlinear Stochastic Systems
ACC, 2005
[6] M. Toussaint:
Robot Trajectory Optimization using Approximate Inference
ICML, 2009

Hi Marc, thank you very much for the interesting and informative post! I think that the reason that the linearization matrices (A_t, B_t, o_t) are estimated with a neural network is that they are not constant, as the change depending on the current encoded latent representation z_t. This makes the transition model non-linear. On the other hand, the “Global E2C” model is presented where the matrices are directly estimated as you state.
LikeLiked by 1 person
If you do a local linearization you would also get matrices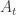 etc. I’m also not sure what the training inputs are if you learn the matrices with a neural network.
etc. I’m also not sure what the training inputs are if you learn the matrices with a neural network.
LikeLiked by 1 person
The proposed approach jointly learns feature extraction that favors linear transitions and linear dynamics that suit with the representation. It makes the learnt dynamics suit well with the latent representation and vice versa. The training is performed in one big optimization problem that accounts for both the transition model and the inference model.
So maybe they introduced another neural network for such joint learning approach?
LikeLike
This approach jointly learns feature extraction that favors linear transitions and linear dynamics that suit with the representation. It makes the learnt dynamics suit well with the latent representation and vice versa. In fact, the training is performed in one big optimization problem that accounts for both the transition model and the inference model.
So maybe they introduced another neural network for such joint learning approach?
LikeLike
I blog quite often and I truly appreciate your infiomatron. Your article has truly peaked my interest. I’m going to book mark your blog and keep checking for new details about once per week. I subscribed to your RSS feed too.
LikeLike